

PAN-OS(含 Panorama)のカスタムレポート機能は、スケジュールで1日1回のレポートを作成する利用方法、もしくはWeb-UIのカスタムレポート内の”Run Now”ボタンからオンデマンドで作成する利用方法があります。1時間毎にカスタムレポートを作成したい場合や自動化したい場合、どちらの方法も微妙な感じです… そこで、今回はPAN-OS(含 Panorama)のAPIを使用して、動的にカスタムレポートのデータを取得する方法を試してみました。
事前準備
PAN-OS(含 Panorama)のAPIのおさらい
- API経由でコマンドをリクエストする際には、API-key(認証済み情報)が必要になります。誤ったAPI-keyを含めてAPIコマンドを実行した場合、認証エラーとなりリクエストしたAPIコマンドは実行できません。
- API-keyは、APIを叩く権限のあるユーザーアカウント、パスワードから作成します。
PAN-OS(含 Panorama)のAPI利用時の基本動作は、こんなイメージになります。

PAN-OS(含 Panorama)でAPI用のアカウント作成と権限付与
PAN-OS(含 Panorama)でAPIを利用する場合、セキュリティ面を考慮し、API用のアカウントの作成・権限付与を推奨します。今回は、Panoramaを使用してますが、PAN-OSの場合も同様になります。
- API用アカウントの権限の設定
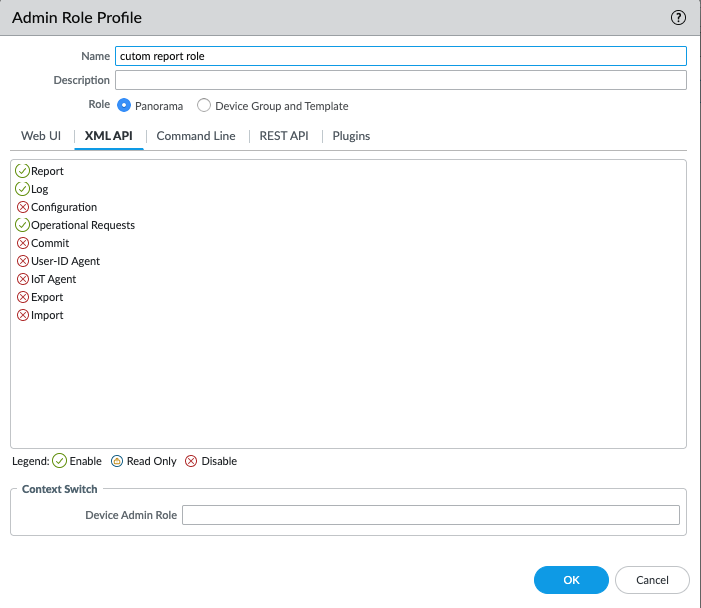
【Panoramaタブ】> Admin Roles > Add からAdmin Role Profileの画面を開き、”XML-API”タブでAPI用のアカウントに付与する権限を選択します。今回の例では、”Report”, “Log”, “Operation Requests”を実行できる権限を付与しています。 APIを実行するのに不要な権限(例 “Web-UI”タブ配下などの操作権限)は、Disable設定とするのが推奨になります。
- API用アカウントの設定
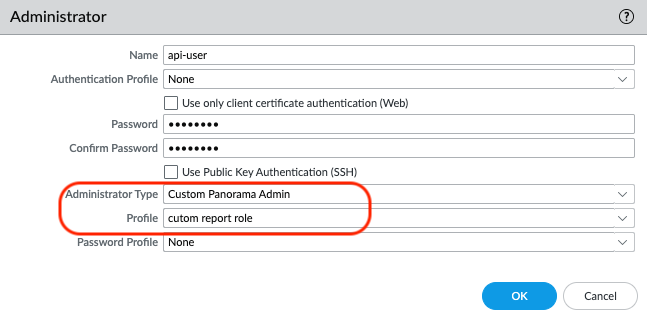
【Panoramaタブ】> Administrators > Add からAdministratorの画面を開き、Administrator Typeで”Custom Panorama Admin”を選択し、ProfileでAPI用アカウントの権限のプロファイルを指定します。
カスタムレポートの定義
API経由で動的にカスタムレポートを作成する場合、取得したいカスタムレポートの中身をXMLで定義する必要があります。ゼロからXMLでカスタムレポートを定義するのは、かなり高度なので、今回はPanoramaのWeb-UIで取得したいカスタムレポートを作成し、configファイルから該当のカスタムレポートのXML部分を抜き出してます。(カスタムレポートの作成方法は、こちらを参照下さい。)
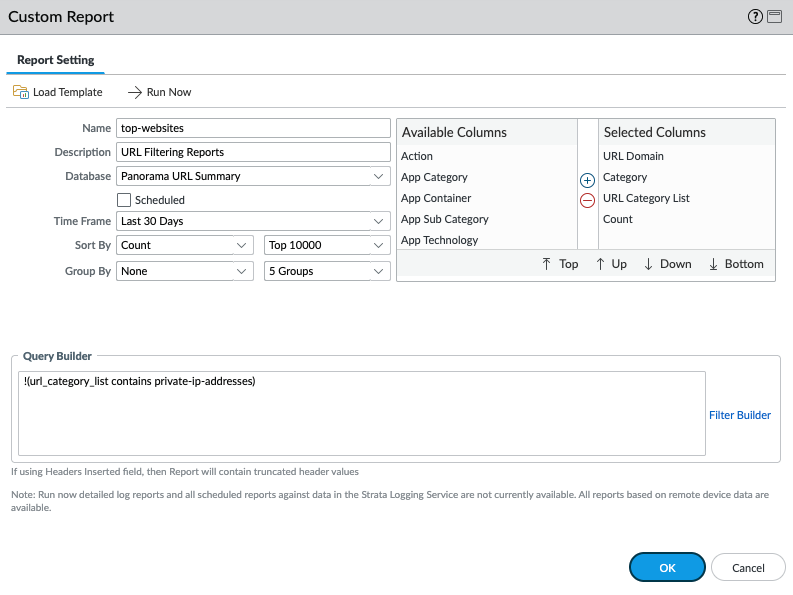
サンプルのカスタムレポートは、こんな感じです。configを保存し、ダウンロードしたconfigファイル内で、このサンプルのカスタムレポートのXML部分を抽出し、テキストファイルに保存します。
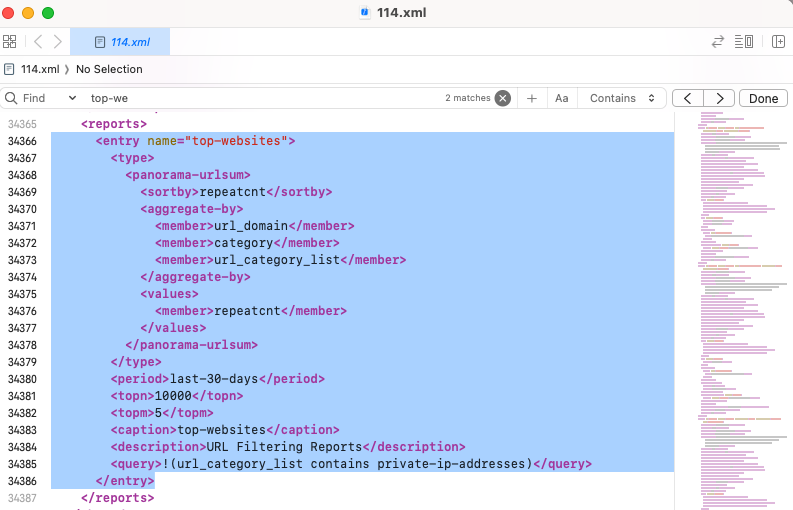
テキストファイルに保存したカスタムレポートの定義内容が、こちらです。
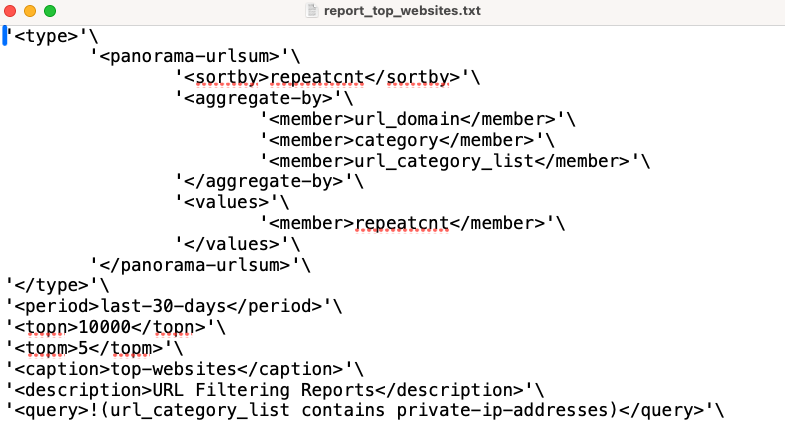
カスタムレポートの中身をテキストファイルにする際は、<entry name = “xxxxxxxxxx”> 及び </entry> の部分は不要です。今回作成するスクリプトは、スクリプトを実行する際にカスタムレポートの定義ファイルを読み込み、APIコマンドのクエリーにカスタムレポートの定義内容を含める仕様にしています。別の内容のカスタムレポートを同様に作成し、スクリプトを実行する際にカスタムレポートの定義ファイル部分を変更する(-r オプションで読み込むファイル名を変更する)ことで、対応できるようにしています。
APIを実行する対象(Panorama)の情報ファイルの作成
APIを実行する対象のPanoramaの情報をyamlファイルに保存します。yamlファイル内のcommon, url, user, passwordですが、今回のスクリプトでは、それぞれの文字をキーにして値を呼び出してます。(common, url, user, password部分を変更した場合、スクリプト内の該当箇所も合わせて変更して下さい。)
| PanoramaのIPアドレス or FQDN | (例) https://1.1.1.1 |
| API用のアカウント | (例) admin |
| API用のアカウントのパスワード | (例) password |
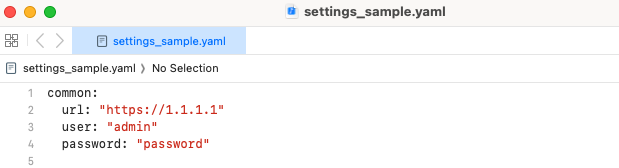
ファイルの保存
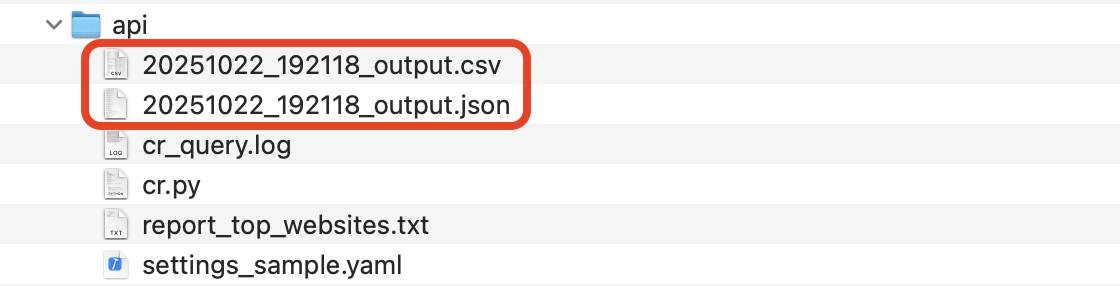
スクリプトファイル(今回の例の場合、cr.py)、カスタムレポートの定義ファイル(今回の例の場合、report_top_websites.txt)、yamlファイル(今回の例の場合、settings_sample.yaml)が用意できたら、同一のディレクトリーに保存します。

スクリプトの実行
スクリプトを実行するには、ファイルを保存したディレクトリーでpython3コマンドを実行します。今回のスクリプトでは、実行時に下記のオプション指定する様になってます。
- -y オプション: yamlファイルを指定 [ 省略不可 ]
- -r オプション: カスタムレポートの定義ファイルを指定 [ 省略不可 ]
- -wt オプション: (Panorama側の)カスタムレポート作成jobの待ち時間(秒)を指定 [省略時は10秒]

実行結果
定義したカスタムレポートのデータが存在する場合、実行時間をファイル名にしてjson, csvファイルを作成します。定義したカスタムレポートのデータが存在しない場合(“No matching data”の場合)、ログにデータが存在しない旨を記録します。
スクリプトの仕様
スクリプトの仕様
今回作成したスクリプトの仕様は、こんな感じです。
- スクリプトの実行時のログを下記に保存可能
- コンソール (デフォルト: 表示しない。表示する場合は、ログハンドラーを調整)
- ファイル (デフォルト: cr_query.logファイルに保存)
- syslogサーバー (デフォルト: 送付しない。送付する場合は、アドレスを指定しコメントイン)
- アクセスするPanorama(NGFW)の情報は、yamlファイルから読み取る (-y オプション)
- クエリーするカスタムレポートは、カスタムレポート定義ファイルから読み取る (-r オプション)
- Panorama(NGFW)でのカスタムレポート作成の待ち時間は、デフォルト: 10秒
任意の待ち時間(秒)を指定する場合は、(-wt オプション) を使用 - カスタムレポート作成のjobをクエリーした後は、待ち時間経過後にjobのステータスを確認
- jobのステータスが FIN の場合、カスタムレポートのデータをパース
- データが存在する場合 :データを格納
- データが存在しない場合:ログにNo mathching dataを記録
- jobのステータスが ACT の場合、3回までリトライする
リトライの間隔は、リトライ回数に応じて 回数 x 待ち時間 (秒)- 3回リトライして、ステータスがFINにならない場合は、異常終了
- jobのステータスが FIN の場合、カスタムレポートのデータをパース
- カスタムレポートのデータが存在する場合は、実行時間をファイル名にしてjson形式、csv形式で保存
スクリプト実行時の動作イメージ
上記の仕様をイメージにするとこんな感じになります。

スクリプトの中身
上記のフローをスクリプトにしたら、こんな感じになります。

スクリプト全体は、こんな感じです。
import sys
import json
import csv
import yaml
import time
import requests
import urllib3
import os
from bs4 import BeautifulSoup
from argparse import ArgumentParser
from os.path import abspath, dirname, join
from datetime import datetime
from logging import getLogger, DEBUG, ERROR, StreamHandler, FileHandler, Formatter, handlers
from urllib3.exceptions import InsecureRequestWarning
urllib3.disable_warnings(InsecureRequestWarning)
logger = getLogger(__name__)
logger.setLevel(DEBUG)
log_format = "%(asctime)s %(name)s:%(lineno)s %(funcName)s [%(levelname)s]: %(message)s"
# logging and output to console
st_handler = StreamHandler(sys.stderr)
st_handler.setLevel(ERROR) # log streaming level control, comment-out >= debug, comment-in >= error
st_handler.setFormatter(Formatter(log_format))
logger.addHandler(st_handler)
# logging and output to file
fl_handler = FileHandler(filename="./cr_query.log", encoding="utf-8")
#fl_handler.setLevel(ERROR) # log filing level control, comment-out >= debug, comment-in >= error
fl_handler.setFormatter(Formatter(log_format))
logger.addHandler(fl_handler)
# when sending logs to syslog server, comment-in
"""
# logging and output to syslog
address = ('localhost', 514) # setup syslog server IP instead of 'localhost'
sys_handler = handlers.SysLogHandler(address=address)
#sys_handler.setLevel(ERROR) # log filing level control, comment-out >= debug, comment-in >= error
sys_handler.setFormatter(Formatter(log_format))
logger.addHandler(sys_handler)
"""
def args():
# CLI interface, help
usage = 'python3 {} [--yaml yaml] [--report report] [--waittime waittime][--help] '.format(__file__)
argparser = ArgumentParser(usage=usage)
argparser.add_argument('-y', '--yaml', type=str, help='select the Panorama yaml file' )
argparser.add_argument('-r', '--report', type=str, help='select the Custom Report Format file' )
argparser.add_argument('-wt', '--waittime', type=int, default=10, help='input the Wait Time [intreger] for query ')
args = argparser.parse_args()
if (args.yaml is None) or not (os.path.isfile(args.yaml)):
logger.error('a yaml file is missing or does not exist, please select a Panorama yaml file')
sys.exit(0)
elif (args.report is None) or not (os.path.isfile(args.report)):
logger.error('Custom Report Format file is missing or does not exist, please select Custom Report Format file')
sys.exit(0)
else:
logger.info('Success: Open yaml file and Report file, and get a valid wait time')
return(args.yaml, args.report, args.waittime)
def api_call(fqdn, target_url):
try:
r = requests.get(target_url, verify=False, timeout=(6.0, 7.5))
if r.status_code != 200:
if r.status_code == 403:
response = BeautifulSoup(r.text, 'html.parser')
msg = response.find("msg")
logger.error('ERROR: ' + msg.string + ' from ' + fqdn)
return
else:
response = BeautifulSoup(r.text, 'html.parser')
msg = response.find("msg")
if msg:
logger.error('ERROR: ' + msg.string + ' from ' + fqdn)
logger.error('ERROR: http response status code: ' + str(r.status_code) + ' from '+ fqdn +', somthing is wrong....')
return
else:
response = BeautifulSoup(r.text, 'html.parser')
logger.info('Success: get response from ' + fqdn )
return(response)
except:
logger.error('ERROR: NO response (or Timeout) from Panorama:',fqdn,', something is wrong with Panorama-ip or network')
return
def build_query1(baseurl, user, password):
query = baseurl + '/api/?type=keygen&user=' + user + '&password=' + password
logger.info('Success: build query1')
return(query)
def parse1(resp):
if resp is None:
apikey = None
logger.error('ERROR: Fail to get api-key ')
sys.exit(0)
else:
key = resp.find("key")
apikey = key.string
logger.info('Success: Get api-key ')
return(apikey)
def build_query2(baseurl, apikey, report_data):
with open(join(dirname(abspath(__file__)), report_data )) as f:
report_format = f.read()
query = baseurl + '/api/?key=' + apikey + '&type=report&reporttype=dynamic&reportname=custom-dynamic-report&async=yes&cmd=' + report_format
logger.info('Success: build query2')
return(query, report_format)
def parse2(resp):
if resp is None:
logger.error('ERROR: something is wrong with recieved Custom Report Query .')
sys.exit(0)
else:
job = resp.find("job")
jobid = job.string
logger.info('Success: Get job-id: ' + jobid)
return(jobid)
def build_query3(baseurl, apikey, jobid):
query = baseurl + '/api/?key=' + apikey + '&type=op&cmd=<show><report><id>' + jobid + '</id></report></show>'
logger.info('Success: build query3')
return(query)
def parse3(resp, counter, report_format, wait_time):
if resp is None:
logger.error('ERROR: something is wrong with recieved Custom Report Query.')
sys.exit(0)
else:
soup = BeautifulSoup(report_format, 'html.parser')
member = soup.find_all("member")
for i in range(0, len(member)):
member[i] = member[i].text
status = resp.find("status")
status = status.string
logger.info('Custom report precessing status: ' + status)
if status == "FIN":
logger.info('Success: Get Custom Report ')
output = {}
#print(resp)
report = resp.find("report")
if report.get_text(strip=True):
logger.info('Custom Report was created, data is available.')
entry = report.find_all("entry")
for tag1 in range (0, len(entry)):
line = {}
for i in range(0,len(member)):
line.update({member[i] : entry[tag1].find(member[i]).text})
output[tag1] = line
return(output, status, member)
else:
logger.info('Custom Report was created, but No matching data for the query')
sys.exit(0)
elif status == "ACT":
logger.info('Processing the Custom Report, please wait for ' + str((wait_time * (counter + 1))) + ' seconds')
logger.info('Retry to check Custom Report Job, retry count: ' + str(counter + 1))
time.sleep(wait_time * (counter + 1))
else:
logger.error('something is wrong with .... ')
return(None, status, None)
def display(data, member):
if not data:
logger.info('No Custom Report.')
else:
num = len(data)
logger.info( str(num) + ' entries in the Custom Report.')
#print(json.dumps(data, indent=4))
dt_now = datetime.now()
filename = dt_now.strftime('%Y%m%d_%H%M%S_')
with open('./' + filename+ 'output.csv','w',newline='') as f:
writer = csv.writer(f, lineterminator='\n')
header = []
for j in range(0, len(member)):
header.append(member[j])
header_tuple = tuple(header)
writer.writerow(header_tuple)
for i in range(0, len(data)):
line = []
for j in range(0, len(data[i])):
line.append(data[i][header[j]])
writer.writerow(line)
f.close()
logger.info ('SUCCESS: to create csv file')
with open('./' + filename+ 'output.json', 'w') as f:
json.dump(data, f, indent=4)
f.close()
logger.info ('SUCCESS: to create json file')
def main():
yaml_data, report_data, wait_time = args()
with open(join(dirname(abspath(__file__)), yaml_data )) as f:
settings = yaml.safe_load(f)
target_url = build_query1(settings['common']['url'], settings['common']['user'], settings['common']['password'])
resp1 = api_call(settings['common']['url'], target_url)
apikey = parse1(resp1)
#print('apikey:', apikey)
target_url, report_format = build_query2(settings['common']['url'], apikey, report_data)
resp2 = api_call(settings['common']['url'], target_url)
jobid = parse2(resp2)
#print('jobid: ', jobid)
target_url = build_query3(settings['common']['url'], apikey, jobid)
logger.info ('wait for ' + str(wait_time) + ' seconds to next api-call, due to requested custom report is processing at server side')
time.sleep(wait_time)
job_status = "INIT"
counter = 0
while job_status != "FIN":
resp3 = api_call(settings['common']['url'], target_url)
output, job_status, member = parse3(resp3, counter, report_format, wait_time)
counter += 1
if (counter > 3) and (job_status !="FIN"):
logger.error ('ERROR: It takes too much time to create custom reports, so break out while-loop')
break
#print(output)
display(output, member)
if __name__ == '__main__':
main()
Panorama側で使用しているオレオレ証明書に付随するエラーを回避するために、api-call 関数内のrequestsのパラメーターで “verify=False” を使用していたり、warningメッセージを非表示にするために urllib3.disable_warnings(Insecure RequestWarning) を使用しています。この辺は、実環境に合わせてチューニングして下さい。このスクリプトのまま使用する場合、証明書に関連するセキュリティ的な問題は、自己責任でお願いします。また、beautiful soupなどの外部 library も使用しています。インストールされていない環境の場合、インストールをお願いします。
こちらで試した限り、意図した通りの動作になってます。もしバグなどありましたら、コメントお願いします。

コメント欄 質問や感想、追加してほしい記事のリクエストをお待ちしてます!